Hoy cumple exactamente 31 días de grabación de corrido, en estos 31 días, como únicamente graba –y toma instantáneas– a 640×480 si detecta movimiento, me ha generado un total de 154579 archivos entre fotografías y videos, 7Gb de información:
~ # du -sh /home/dvr/video/
7.3G /home/dvr/video/
Así que con un disco de 80Gb que tiene supera ampliamente mis estimaciones iniciales, tengo para grabar sin tener que borrar nada apróximadamente 10 meses de corrido, mejor que cualquier DVR comprada con disco de 320Gb.
Para que veas todo el mundo que te rodea en modo texto, de preferencia verde sobre fondo negro
Se puede loguear texto arbitrario a syslog desde cualquier PC corriendo Linux en la red simplemente por medio del comando «logger» (sin las comillas).
La salida de logger va a parar derechito a syslog y es accesible desde /var/log/messages:
~ # logger puto el que lee
~ # tail /var/log/messages
Nov 10 23:30:01 dvr cron[12109]: (root) CMD (test -x /usr/sbin/run-crons && /usr/sbin/run-crons )
Nov 10 23:40:01 dvr cron[12161]: (root) CMD (test -x /usr/sbin/run-crons && /usr/sbin/run-crons )
Nov 10 23:46:25 dvr root: puto el que lee
Hasta ahí nada de otro mundo, un comando que por si solo no tiene mucha magia, manda texto al syslog, ¿Y?
Por si solo no resalta en absoluto pero: ¿Qué pasa cuando necesitás loguear a syslog la salida de un comando cualquiera que por defecto va a la pantalla y no a syslog?
¡Bingo! Usando un pipe es cuestión de redireccionar la salida a logger para tenerlo accesible desde /var/log/messages, desde la red en el syslog server y desde la página web para mayor comodidad. Supongamos que quiero loguear la salida de ping a uno de los DNS de google:
~ # ping 8.8.8.8 -c2 | logger
~ # tail /var/log/messages
Nov 10 23:40:01 dvr cron[12161]: (root) CMD (test -x /usr/sbin/run-crons && /usr/sbin/run-crons )
Nov 10 23:46:25 dvr root: puto el que lee
Nov 10 23:50:01 dvr cron[12220]: (root) CMD (test -x /usr/sbin/run-crons && /usr/sbin/run-crons )
Nov 10 23:56:17 dvr logger: PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
Nov 10 23:56:17 dvr logger: 64 bytes from 8.8.8.8: icmp_req=1 ttl=47 time=178 ms
Nov 10 23:56:18 dvr logger: 64 bytes from 8.8.8.8: icmp_req=2 ttl=47 time=178 ms
Nov 10 23:56:18 dvr logger:
Nov 10 23:56:18 dvr logger: --- 8.8.8.8 ping statistics ---
Nov 10 23:56:18 dvr logger: 2 packets transmitted, 2 received, 0% packet loss, time 1001ms
Nov 10 23:56:18 dvr logger: rtt min/avg/max/mdev = 178.639/178.658/178.677/0.019 ms
¿Cuantas veces necesitaste conocer cuanto espacio ocupa un directorio en particular? Desde la consola al ejecutar «du» por «Disk Ussage«:
~ # du /home/dvr/video/movie/
Te devuelve el tamaño en bloques del directorio en cuestión:
48004 /home/dvr/video/movie/
Como al sistema de archivos lo formateé en su momento con un tamaño de bloque de 1024 bytes –Por defecto se usan 4096 bytes si no se especifica un valor diferente para el parámetro en el argumento de la utilidad que formatea-, la cuenta es facil: 48004 bloques de 1024 bytes cada uno suman 49156096 bytes.
Como no podía ser de otra forma, para no tener que andar haciendo cálculos estrambóticos, se le puede pasar a la utilidad como argumento «-h» por «Human Readable» para que devuelva el resultado en formato entendible por humanos:
~ # du /home/dvr/video/movie/ -h
47M /home/dvr/video/movie/
Como el comando es recursivo, puede que te interese además agregarle la opción «-s» por «silent» para que cuando tenga que navegar muchos subdirectorios para sacar la cuenta no te llene la pantalla de texto. La otra muy util que tiene de entre tantas opciones disponibles es la posibilidad de producir un «gran total» con la opción «-c«, por ejemplo:
~ # du /home/dvr/video/movie/ -csh
47M /home/dvr/video/movie/
47M total
2 – Conocer el espacio utilizado/disponible por partición
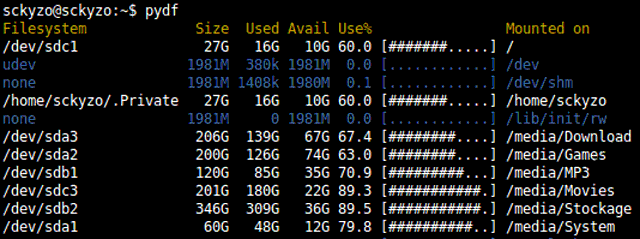
Con la salida en modo «bloques» para el comando «df» por «Disk Free«:
~ # df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/sda3 9297812 1988296 6837208 23% /
/dev/sdb1 397475 295084 75886 80% /usr/portage
/dev/sdb2 78628740 6382688 72246052 9% /home
O en modo «Human Readable» pasándole el argumento «-h«:
¿Quién no se manda una metida de pata cada tanto? Yo tengo varias de diversa índole en prácticamente todos los aspectos de la vida. Estas son las mejores que puedo recordar que me hayan pasado en Linux tipeando comandos en la consola:
Ejecutar comandos en el host equivocado:
Ejecutar un comando creyendo estar en la consola local cuando en realidad se trataba de una jaula chroot o un host remoto:
# reboot
# halt
# killall (nombre de proceso importante)
De a poco se me ha hecho costumbre cambiarle el nombre al shell ni bien inicio sesión remotamente. Si me logueo en un Host cuyo nombre es pepito, renombro el prompt para que lo refleje:
# export PS1=”[pepito] $PS1”
Cambiar el puerto del servidor SSH
Eso, por muy boludo que suene ya me pasó unas dos o tres veces cambiar el puerto en el que escucha el servidor SSH y olvidarme de modificar el reenvío de puertos en el router que hace NAT o en el Firewall con lo que me encierro solo del lado de afuera y no puedo volver a conectarme remotamente:
De ahí viene la costumbre que tengo de instalar una VPN que traspase el firewall en cuanto servidor tengo bajo mi control.
Bajar la interface WAN en lugar de la LAN
Estando logueado por SSH, en lugar de bajar eth1 que era la interface LAN, bajé eth0 que era la WAN. El servidor se queda sin internet, yo me quedo fuera sin conexión. El servidor está a 70 kilómetros de distancia y es domingo a la siesta, nada mas que hacer hasta el lunes a la mañana en que alguien físicamente pueda solucionar el “problemita” reinciando el servidor o levantando eth0 nuevamente.
ifconfig eth0 down
Desde entonces tengo la costumbre de usar variables para asignarle nombres a las interfaces de red y usar la variable en lugar del nombre en el script:
export wan=eth0
Compilar mal el kernel
En un servidor remoto, compilar mal el kernel y reiniciar para probarlo resultando en un kernel panic o en quedarme sin conectividad en el servidor imposibilitando la reconexión remota por SSH para verificar los cambios.
make –j4 && make modules_install && cp arch/i386/boot/bzImage /boot/kernel && reboot
Desde entonces, si necesito reiniciar un host linux que no se si va a volver a la vida después del reboot uso una combinación de este watchdog en caso de pérdida de conectividad con este sistema de reinicio automático en caso de kernel panic y el método fallback que provee grub –ya voy a escribir al respecto alguna vez– para asegurarme de que si algo me salió mal, el equipo se reinicie solo volviendo a usar la configuración anterior en donde todo funcionaba.