A este le puse por título TIP por que no es mas que eso: otro ayuda memoria para la posteridad, a saber:
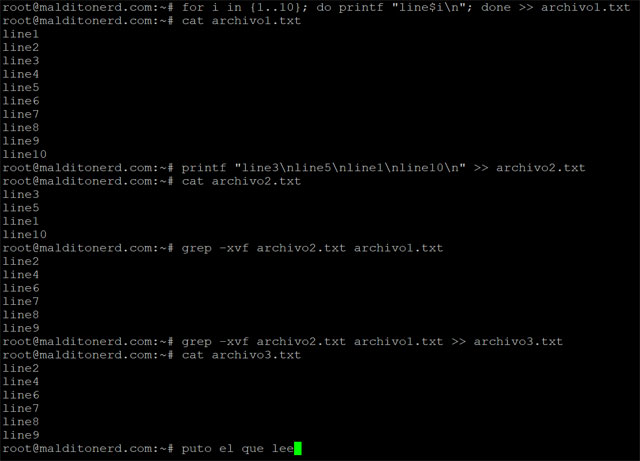
- Tenés dos archivos con texto: archivo1 y archivo2 como en el ejemplo de la captura de pantalla.
- Necesitás identificar las líneas duplicadas o simplemente restarlas como en el ejemplo y mostrar únicamente las que no se repiten.
La única forma que conozco de lograr esto en Bash sin recurrir a complicados regex de la muerte forma mas rápida de lograr esto sin tener que pensar mucho es como tantas otras veces: GREP. Alguien debería hacerle un pedestal al autor original de grep, sin duda.
Los switchs que vas a utilizar en grep son:
- -x match únicamente si toda la línea coincide.
- -f para en lugar de utilizar stdin o una palabra como argumento, usar un archivo, de a una línea por vez.
- -v para reverse search, restar las líneas que coincidan en archivo2 de archivo1.
Utilizar grep en Bash para restar el contenido de un archivo de otro linea a linea en la consola de comando de Linux