Esta que sigue me pasó hace un rato y no es la primera vez lamentablemente: el log de <algo> te llena el disco de mierdas y se te rompe alguna otra cosa que estaba en producción y el mundo se desploma por una fracción de hora hasta que reaccionás y todo vuelve a la normalidad.
Unas veces la sacás barata y no pasa de un susto, otras se te corrompe el sistema de archivos de una VM o el log de una base de datos o no te queda otra que restaurar ese <algo> que no funciona desde el backup que por suerte tenías.
Por que si estás a cargo de un sistema cualquiera y no tenés nada que te avise que se te llenó un disco, un backup seguramente tenías, verdad?
Foto de un sysadmin real pensando que hacer después de que se le llenó un disco, borró el log y ahora no le funciona nada.
Bueno, acá va: esta es la forma rápida de devolver a la vida, de resucitar un Linux cuando dejó de funcionar por que se quedó sin espacio en tal o cual disco, usualmente la partición raíz, por que si no tenés nada que te avise que se te llenó un disco, ni tenés backup, tampoco tenés compartimentado el disco en particiones, verdad?
Muy pero muy provisorio, ya lo iré mejorando de a poquito. A ver si consigo hacerme de un script mas o menos como el que me hice para reproducir youtube usando mplayer con un combo de teclas que me automatice el proceso un día de estos, pero mientras tanto dentro de lo poco que he podido avanzar hasta ahora:
Como usar mplayer (o cualquiera sea tu reproductor de cabecera en Linux) para ver series y películas desde cuevana.tv
¿Por que? Por que Flash para Linux apesta.
El reproductor basado en flash de cuevana.tv en Linux a pantalla completa el solito se lleva una buena tajada del uso del microprocesador. Si no disponés de una PC potente y una buena placa de video, al ver cuevana en pantalla completa el video va dando saltitos. Lo mismo para todos aquellos excluídos que por una razón u otra se han quedado fuera de la carrera:
Los que tienen una placa de video tan nueva que Linux todavía no la soporta al 100%
Los que tienen una placa de video tan vieja que ya no consiguen un driver compatible con su flamante instalación de Linux por que Xorg –que no nos quiere a los tercermundistas– ya la considera: «Deprecated».
Por otro lado:
¿Compilar y ver cuevana al mismo tiempo desde la página web? Imposible.
¿Compilar y ver cuevana usando mplayer? Coser y cantar.
El truco está en dejar al reproductor de cuevana almacenando en buffer –descargando-, pero detenido –con la reproducción pausada-. Mientras esto ocurre, tu navegador está bajando desde internet el video en cuestión en formato MP4. Para hacerlo lo mas universal posible, veamos el ejemplo de Mozilla Firefox.
El directorio de configuración de Mozilla Firefox siempre se almacena en tu carpeta personal, en un subdirectorio de nombre: «.mozilla», normalmente oculto y que podés pedirle a tu gestor de ventanas que te muestre presionando CTRL + H.
Dentro de .mozilla se aloja a su vez otro subdirectorio: «firefox», que contiene toda la configuración de este último. Todo lo que el navegador descarga desde internet lo almacena por lo general en un subdirectorio dentro de .firefox de nombre totalmente aleatorio, de 8 carateres de longitud y extensión .default. A mi en esta instalación me tocó en suerte: 03qrfcll.default
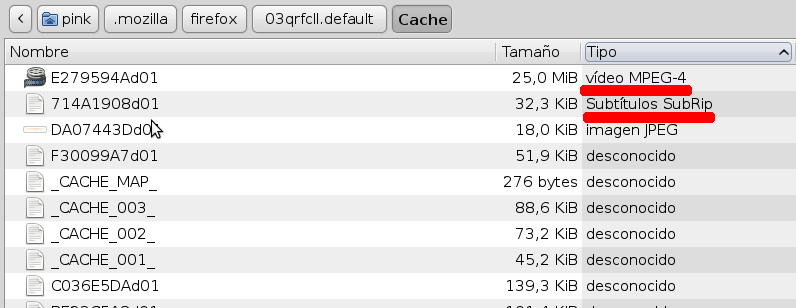
A su vez, dentro de 03qrfcll.default está el subdirectorio «Cache» que es el que andamos buscando, el que contiene el video y el subtítulo que la página web de cuevana nos está descargando en este preciso instante.
¿Cómo saber cuales son de entre la maraña de archivos que hay alojados ahí dentro?
Opción 1 –la mas maricona, para usuarios de KDE, Gnome o XFCE4-: Usando el navegador de archivos, ordenando los archivos por tipo.
Usando el navegador de archivos, ordenando los archivos por tipo para saber cual es el archivo que contiene video y cual el que contiene el subtítulo desde Gnome.
Para que veas todo el mundo que te rodea en modo texto, de preferencia verde sobre fondo negro
Se puede loguear texto arbitrario a syslog desde cualquier PC corriendo Linux en la red simplemente por medio del comando «logger» (sin las comillas).
La salida de logger va a parar derechito a syslog y es accesible desde /var/log/messages:
~ # logger puto el que lee
~ # tail /var/log/messages
Nov 10 23:30:01 dvr cron[12109]: (root) CMD (test -x /usr/sbin/run-crons && /usr/sbin/run-crons )
Nov 10 23:40:01 dvr cron[12161]: (root) CMD (test -x /usr/sbin/run-crons && /usr/sbin/run-crons )
Nov 10 23:46:25 dvr root: puto el que lee
Hasta ahí nada de otro mundo, un comando que por si solo no tiene mucha magia, manda texto al syslog, ¿Y?
Por si solo no resalta en absoluto pero: ¿Qué pasa cuando necesitás loguear a syslog la salida de un comando cualquiera que por defecto va a la pantalla y no a syslog?
¡Bingo! Usando un pipe es cuestión de redireccionar la salida a logger para tenerlo accesible desde /var/log/messages, desde la red en el syslog server y desde la página web para mayor comodidad. Supongamos que quiero loguear la salida de ping a uno de los DNS de google:
~ # ping 8.8.8.8 -c2 | logger
~ # tail /var/log/messages
Nov 10 23:40:01 dvr cron[12161]: (root) CMD (test -x /usr/sbin/run-crons && /usr/sbin/run-crons )
Nov 10 23:46:25 dvr root: puto el que lee
Nov 10 23:50:01 dvr cron[12220]: (root) CMD (test -x /usr/sbin/run-crons && /usr/sbin/run-crons )
Nov 10 23:56:17 dvr logger: PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
Nov 10 23:56:17 dvr logger: 64 bytes from 8.8.8.8: icmp_req=1 ttl=47 time=178 ms
Nov 10 23:56:18 dvr logger: 64 bytes from 8.8.8.8: icmp_req=2 ttl=47 time=178 ms
Nov 10 23:56:18 dvr logger:
Nov 10 23:56:18 dvr logger: --- 8.8.8.8 ping statistics ---
Nov 10 23:56:18 dvr logger: 2 packets transmitted, 2 received, 0% packet loss, time 1001ms
Nov 10 23:56:18 dvr logger: rtt min/avg/max/mdev = 178.639/178.658/178.677/0.019 ms
Típico caso: Recuperación de datos, el medio ha sido sobreescrito con información reciente, con lo que no todos los archivos recuperables a bajo nivel salen sanos.
Lo que haría todo el mundo es abrir archivo por archivo de a uno verificando cuales estan sanos y cuales rotos lo que por resumirlo de alguna manera que englobe totalmente el concepto que quiero transmitir: Es un reverendísimo dolor de bolas.
Acción y efecto de probar todos los archivos recuperados uno por uno para detectar de forma manual cuales están corruptos
Buscar de entre los miles de archivos que nos puedan interesar cuales salieron sanos y cuales se corrompieron de manera manual como hice toda la vida es la parte que mas tiempo y recursos (mentales) consume. Por suerte alguien en los foros de Gentoo –fuente de eterna sabiduría informática si las hay– tuvo la misma inquietud pero además fué un poco mas inteligente que yo, quería hacerlo automáticamente. Ya de entrada venía bien encaminado cuando dijo:
Hola,
Tengo un respaldo de archivos antiguos de mi trabajo (principalmente MSOffice), en algún momento varios archivos se corrompieron, por lo que hay archivos que se pueden abrir y otros que no hay caso.
Quiero eliminar los archivos corruptos.
Para diferenciarlos de los buenos se me ocurrió utilizar el comando «file»
Ahí fué que se me encendió la lamparita y vengo utilizando este método automático desde entonces exitosamente. Es que el comando «file«, puede diferenciar a la perfección un tipo de archivo de otro con lo que cualquier archivo que estuviera corrupto, ya sea una imagen, un video, música o un documento de office en lugar de ser identificado como corresponde, simplemente figurará como de tipo «data«.
Tan sencillo como eso, eliminar del directorio que contiene los archivos recuperados, todos aquellos que figuren como de tipo «data«, a lo que Stolz, moderador del foro y mago programador de Bash respondió con este sencillo script que navega subdirectorios recursivamente eliminando todos los archivos que sean de tipo «data»:
find . -type f | while read linea; do
tipo=`file -b "$linea"`
if [[ $tipo == "data" ]];then
rm "$linea"
fi
done
Paso a paso:
Se crea un archivo dentro de /usr/bin para que contenga al script, lo llamaremos «borrador_de_archivos_corruptos«:
nano /usr/bin/borrador_de_archivos_corruptos
Se copia el contenido del script y se pega dentro del archivo que estamos editando con nano (o el que sea tu editor de texto de cabecera).
Se sale guardando los cambios.
Se convierte el archivo en ejecutable:
chmod +x /usr/bin/borrador_de_archivos_corruptos
Y ya estça listo para usar.
IMPORTANTE: Ejecutar borrador_de_archivos_corruptos únicamente dentro de la carpeta que contiene la información salvada del proceso de recuperación de datos. Ejecutar el script fuera de la misma te va a borrar archivos que son de tipo «data» por que tienen que serlo, te va a hacer mierda todo lo que encuentre a su paso, para que se entienda.
Ya tenés otro motivo mas para tener un Linux siempre a mano.